23.1 Seletividade
1.1 - Seletividade
Nesta seção, introduzimos a seletividade. Este parâmetro é discutido no artigo 19 da RDC Nº 166. Neste, é apontado que a seletividade do método analítico deve ser demonstrada por meio da capacidade de identificar ou quantificar o analito de interesse, inequivocamente, na presença de componentes que podem estar presentes na amostra, como impurezas e componentes da matriz.
Em Gustavo González a seletividade foi definida como o grau em que um método pode quantificar uma substância com precisão na presença de interferências nas condições indicadas do ensaio para a amostra matriz em estudo. Devido a presença de diversas interferências nas condições de ensaio, é impraticável considerar todos as potenciais interferências. Com isso, é aconselhável estudar apenas os piores casos susceptíveis.
Segundo as exigências da RDC nº 166, nos ensaios quantitativos e ensaios limite, a seletividade deve ser demonstrada por meio da comprovação de que a resposta analítica se deve exclusivamente ao analito, sem interferência do diluente, da matriz, de impurezas ou de produtos de degradação.
Por outro lado, para os ensaios de identificação, deve ser demonstrada sua capacidade de obter resultado positivo para amostra contendo o analito e resultado negativo para outras substâncias presentes na amostra. Neste sentido, os ensaios devem ser aplicados a substâncias estruturalmente semelhantes ao analito, sendo o critério de aceitação a obtenção de resultado negativo.
Para este parâmetro, o único estudo estatístico apontado é o de efeito matriz, o qual tem como objetivo avaliar a interferência dos componentes da matriz no sinal analítico e pode ser aplicado aos ensaios que envolvem matrizes complexas. Todavia, nenhum método estatístico é especificado para os casos nos quais a matriz não é complexa, bem como para avaliar a interferência da presença de outros componentes (tais como impurezas). Nas próximas subseções, apresentamos algumas sugestões de técnicas estatísticas que podem ser utilizadas no estudo de seletividade. Além disso, discutimos em detalhes a metodologia estatística apropriada para o estudo do efeito matriz.
1.1.1 - Técnicas estatísticas sugeridas
A ausência absoluta efeitos de interferência podem ser definidas como “especificidade”. Assim, temos que especificidade = 100 % da selectividade.
A seletividade de um método pode ser expressa quantitativamente usando a proporção máxima tolerada, isto é, a razão da concentração de interferência de analito dividido por uma perturbação sobre a resposta analítica que produz uma concentração de analito. A equação de medição da proporção máxima tolerada (recuperação) é dada por:
$$\text{Rec}=\frac{C_o}{C_t}\times100$$
em que
- Rec: é a recuperação, em ($ \char37 $);
- é a concentração obtida em $ mg/mL; $
(há elementos em falta na equação acima)
- é a concentração teórica em $ mg/mL; $
(há elementos em falta na equação acima)
Consideremos uma amostra aleatória simples $ \text{Rec}_1,\text{Rec}_2,\ldots,\text{Rec}_n $, obtida de uma população com distribuição normal, com média $ \mu=100 $ e variância $ \sigma^2 $ desconhecidas. Como neste caso a variância é desconhecida, utilizaremos a variância amostral $ s^2 $ no lugar de $ \sigma^2 $. Assim, temos que
$$T=\frac{|\overline{\text{Rec}}-100|}{s/\sqrt{n}}\sim t_{(n-1)}\quad ~(1)$$
ou seja, a variável $ T $ tem distribuição t de Student com $ n-1 $ graus de liberdade.
Então, ao fixarmos o nível de significância $ \alpha $, obtemos da Tabela da distribuição t de Student com $ n-1 $ graus de liberdade, o valor $ t_{((n-1),\alpha/2)} $, que satisfaz
$$\mathbb{P}\left(-t_{((n-1),\alpha/2)}\leq T\leq t_{((n-1),\alpha/2)}\right)=1-\alpha$$
Analogamente ao caso anterior, obtemos que
$$\mathbb{P}\left(-t_{((n-1),\alpha/2)}\leq \frac{\overline{\text{Rec}}-100}{s/\sqrt{n}}\leq t_{((n-1),\alpha/2)}\right)=1-\alpha$$
ou seja,
$$\mathbb{P}\left(\overline{\text{Rec}}-t_{((n-1),\alpha/2)}\frac{s}{\sqrt{n}}\leq100\leq \overline{\text{Rec}}+t_{((n-1),\alpha/2)}\frac{s}{\sqrt{n}}\right)=1-\alpha.$$
Logo, o intervalo com $ 100(1-\alpha)\char37 $ de confiança para $ \mu=100 $, com variância desconhecida, será dado por
$$IC(\mu=100,1-\alpha)=\left(\overline{\text{Rec}}-t_{\alpha/2}\frac{s}{\sqrt{n}};\overline{\text{Rec}}+t_{\alpha/2}\frac{s}{\sqrt{n}}\right).$$
Para facilitar a execução do teste, podemos seguir os passos:
- Estabelecer as hipóteses:
Fixamos $\mu=\mu_0=100 $.
(há elementos em falta na equação acima)
$\mu\neq\mu_0 \quad \text{(teste bilateral)} $;
(há elementos em falta na equação acima)
-
Fixar o nível de significância $ \alpha $.
-
Determinar a região crítica.
Como o teste é bilateral, determinamos os pontos críticos $ -t_{\alpha/2} $ e $ t_{\alpha/2} $ tais que $ \mathbb{P}[T \ > \ t_{\alpha/2}]=\mathbb{P}[T \ < -t_{\alpha/2}]=\alpha/2 $ a partir da distribuição t de Student com $ n-1 $ graus de liberdade.
- Calcular, sob a hipótese nula, o valor:
$$T_{\text{obs}}=\frac{|\overline{\text{Rec}}-100|}{\frac{s}{\sqrt{n}}}$$
em que
- $ \overline{\text{Rec}} $: valor da média da recuperação.
- $ s $: valor do desvio padrão amostral.
- $ n $: tamanho da amostra.
- Critério:
Teste bilateral: se $ T_{\text{obs}} \ > \ t_{\alpha/2} $ ou se $ T_{\text{obs}} \ < \ -t_{\alpha/2} $, rejeitamos $ H_0 $. Caso contrário, não rejeitamos $ H_0 $.
(imagem em falta)
- O p-valor no teste bilateral é dado por
$$\text{p-valor} = \mathbb{P}[|t| \ > \ |T_{\text{obs}}||H_0]=2\mathbb{P}[T \ > \ |T_{\text{obs}}| | H_0].$$
- Como vimos anteriormente o intervalo de confiança é dado por
$$IC(\mu,1-\alpha)=\left(\overline{\text{Rec}}-t_{\alpha/2}\frac{s}{\sqrt{n}};\overline{\text{Rec}}+t_{\alpha/2}\frac{s}{\sqrt{n}}\right)$$
Segundo Gustavo González [2], a estatística do teste (equação 1) por ser escrita como:
$$T=\frac{\overline{\text{Rec}}-100}{u(\text{Rec})}$$
em que
$$u(\text{Rec})=\sqrt{\left(\frac{\partial \text{Rec}}{\partial C_o}\right)^2u^2(C_o)+\left(\frac{\partial \text{Rec}}{\partial C_t}\right)^2u^2(C_t)+u^2(\varepsilon)}$$
no qual
- Rec: é a recuperação, em (%);
- é a concentração obtida em $ mg/mL. $ A incerteza é dada pela preparação da amostra (para mais detalhes consulte cálculo de incerteza devido às soluções)
(há elementos em falta na equação acima)
- é a concentração teórica em $ mg/mL; $ A incerteza é dada pelo certificado da solução de referência (ISO GUIDE);
(há elementos em falta na equação acima)
- é o desvio padrão da média dada por $ s/\sqrt{n}. $
(há elementos em falta na equação acima)
Além disso, temos que:
$$\frac{\partial \text{Rec}}{\partial C_o}=\frac{1}{C_t}$$
$$\frac{\partial \text{Rec}}{\partial C_t}=-\frac{C_o}{C^2_t}$$
De acordo com o protocolo LGC/VAM descrito no artigo de Gustavo González [2], se o grau de liberdade associados a incerteza da recuperação são conhecidas, T é comparado com o bicaudal valor tabelado $ t_{(\nu,1-\alpha)} $ para o número de graus de liberdade $ \nu $ com $ (1-\alpha)\char37 $ de confiança. E se$ T\leq t_{tab}, $ a recuperação de consenso não é significativamente diferente de 1. Em alternativa, ao invés do $ t_{tab}, $ podemos utilizar o fator de abrangência $ k $ para a comparação. Os valores típicos são $ k=2 $ ou 3 para 95% ou 99% de confiança, respectivamente. Assim
Se $ \frac{|\overline{\text{Rec}}-100|}{u(\text{Rec})}\leq k $, a recuperação não é significativamente diferente de 100;
Se $ \frac{|\overline{\text{Rec}}-100|}{u(\text{Rec})}> k $, a recuperação é significativamente diferente de 100 e o resultado analítico tem de ser corrigido por $ \overline{\text{Rec}}. $
Outra forma de avaliação descrita em Gustavo González [2] é avaliarmos os limites aceitáveis dadas pelos órgãos reguladores. No caso da consulta pública, descriminamos na tabela 2.
Exemplo 1.1.1
Nesta seção, foi calculada a incerteza expandida relativa, que corresponde a 0,29%. A seguir, apresentamos os dados coletados.
Padrão 1:
| Massa (mg): | 40,20 |
|---|---|
| Potência (%): | 73,5 |
| Umidade (%): | 4,8 |
| Potência Real (%): | 69,972 |
| 1ª Diluição: | 50 |
| Concentração (mg/mL): | 0,56257 |
| Aliquota (mL): | 5 |
| 2ª Diluição (mL): | 10 |
| Concentração (mg/mL): | 0,28129 |
Preparo da amostra:
| 1ª diluição (mL) | 10 |
|---|---|
| Alíquota (mL) | 1 |
| 2ª diluição (mL) | 1 |
| Concentração teórica (mg/mL) considerando nível 80% | 0,2184 |
Para especificidade normal obtemos as seguintes medições:
| Concentração |
|---|
| 0,201796 |
| 0,203226 |
| 0,194679 |
| 0,199994 |
| 0,195206 |
| 0,185519 |
| 0,209691 |
| 0,186922 |
| 0,184354 |
| 0,192918 |
| Amostra | Massa (mg) | Vol. Pd (mL) | Concentração teórica (mg/mL) | Área (mAU*s) | Concentração média obtida (mg/mL) | Recuperação (%) |
|---|---|---|---|---|---|---|
| 1 | 728,68 | 0,00 | 0,1912 | 7447,27975 | 0,1954 | 102,21 |
Para especificidade normal temos:
$$\text{Rec}=\frac{C_o}{C_t}\times100=\frac{0,1954}{0,1912}\times100=102,21\char37\pm 4,36\char37$$
A seguir, testamos a seletividade através do software Action Stat e obtemos os seguintes resultados:
- Primeiramente apresentamos a função Seletividade no Action Stat. Para acessa-la vamos em Action Stat -> Validação Analítica -> Seletividade/Especificidade
(imagem em falta)
- O próximo passo é preencher a janela da Seletividade
(imagem em falta)
- Por fim, obtemos os seguintes resultados:
(imagem em falta)
(imagem em falta)
(imagem em falta)
Logo, a recuperação está dentro do critério de aceitação.
Exemplo 1.1.2
Nesta aplicação foi testada a seletividade e especificidade do método para Zidovudina com limites de especificação de 95 a 105 de recuperação. Para isto, utilizamos as condições de teste dadas na tabela a seguir:
| Solução | Recuperação |
|---|---|
| Solução Teste | 100,01 |
| Solução Teste + Timina | 100,44 |
| Solução Teste + Impureza B | 100,54 |
| Solução Teste + Timina + Impureza B | 100,5 |
As hipoteses de interesse são:
$$\mu\not=100$$
(há elementos em falta na equação acima)
Seque que $ n=4 $. Então, o calculo da recuperação média é:
$$\overline{Rec}=\sum_{i=1}^4 =\frac{Rec_i}{n}=\frac{100,01+100,44+100,54+100,5}{4}=\frac{401,49}{4}=100,3725$$
A estimativa do desvio padrão é dado por
$$s=\sum_{i=1}^4\frac{(Rec_i-\overline{Rec})^2}{n-1}=\frac{(100,01-100,3725)^2+\cdots+(100,5-100,3725)^2}{4-1}=0,2423$$
Logo, podemos calcular $ T_{obs} $:
$$T_{obs}=\frac{\overline{Rec}-\mu_0}{s/\sqrt{n}}=\frac{100,3725-100}{0,2324/\sqrt{4}}=3,058$$
Considerando $ \alpha = 0,05 $ temos $ t_{3;0,025} = -3,18 $ e $ t_{3;0,975} = 3,18 $. Então como $ T_{obs} \in [-3,18;3,18] $ temos evidências para aceitar a hipótese nula ao nível de significância de $ 5\char37 $, ou seja, a recuperação média é igual a 100.
Podemos também calcular o intervalo de confiança para $ \mu $. Temos que
$$IC(\mu=100,95\char37)=\left(\overline{\text{Rec}}+t_{3;0,025}\frac{s}{\sqrt{n}};\overline{\text{Rec}}+t_{3;0,975}\frac{s}{\sqrt{n}}\right)$$
$$IC(\mu=100,95\char37)=\left(100,3725-3,18\frac{0,2423}{\sqrt{4}};100,3725+3,18\frac{0,2423}{\sqrt{4}}\right) = (99,98; 100,76)$$
1.1.2 - Efeito Matriz
Conforme descrito na RDC 166, o efeito matriz deve ser determinado por meio da comparação entre as curvas de calibração construídas com a SQR do analito em solvente e com a amostra fortificada com a SQR do analito. As curvas devem ser estabelecidas para os mesmo níveis de concentração, utilizando no mínimo 5 concentrações diferentes e em triplicata. O Efeito Matriz segundo guia do MAPA é um estudo de seletividade que objetiva averiguar possíveis interferências causadas pelas substâncias que compõem a matriz amostral gerando, basicamente, fenômenos de diminuição ou ampliação do sinal instrumental ou resposta instrumental. O critério adotado é a avaliação do paralelismo entre as curvas relativas ao analito em solvente e a amostra foriticada com o analito.
Nesta seção, vamos usar o conceito de variável dummy para avaliar o efeito da matriz na metodologia analítica. Variável dummy representa estados ou níveis de fatores, ou seja, representa algo que não possui valores numéricos ou, caso possua, estes valores não têm realmente um significado numérico (como número de lote). A variável dummy relacionada ao efeito matriz pode ser escrita da seguinte maneira,
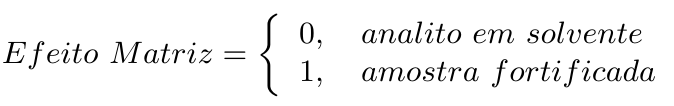
A partir da variável dummy, o modelo de regressão linear completo é dado por:
$$Y_{i}=\beta_0+\beta_1~X_{i1}+\beta_2~X_{i2}+\beta_3~X_{i1}\ast X_{i2}+\varepsilon_{i},\quad i=1,\dots,n \quad (1)$$
em que
- é a variável resposta (Sinal Analítico), que se relaciona com $ p=3 $ variáveis explicativas;
(há elementos em falta na equação acima)
- é o intercepto do modelo;
(há elementos em falta na equação acima)
- é o coeficiente de regressão correspondente a variável explicativa Concentração;
- é a variável explicativa Concentração;
(há elementos em falta na equação acima)
- é o coeficiente de regressão correspondente a diferença no intercepto;
(há elementos em falta na equação acima)
- é a variável dummy (Efeito Matriz);
(há elementos em falta na equação acima)
- é o coeficiente de regressão correspondente a diferença no coeficiente angular (paralelismo);
(há elementos em falta na equação acima)
- representa o erro experimental.
(há elementos em falta na equação acima)
Para entender os testes de comparação de curvas descrito a seguir, observe que:
$$\mathbb{E}[Y_{i}| X_{i1};X_{i2}=1]=(\widehat{\beta}_0+\widehat{\beta}_2)+(\widehat{\beta}_1+\widehat{\beta}_3)~X_{i1}\quad (2)\quad \text{e}$$
$$\mathbb{E}[Y_{i}|X_{i1};X_{i2}=0]=\widehat{\beta}_0+\widehat{\beta}_1~X_{i1}\quad (3)$$
ou seja, para $ X_{i2}=0 $ temos que
$$Y_i=\beta_0+\beta_1~X_{i1}+\varepsilon_i\quad i=1,\dots,n$$
para $ X_{i2}=1 $
$$Y_i=(\beta_0+\beta_2)+(\beta_1+\beta_3)~X_{i1}+\varepsilon_i\quad i=1,\dots,n$$
Então, das equações (2) e (3) temos que a diferença entre as curvas pode ser estimada por:
$$\mathbb{E}[Y_{i}|X_{i1};X_{i2}=1]-\mathbb{E}[Y_{i}|X_{i1};X_{i2}=0]=\widehat{\beta}_0+\widehat{\beta}_2+\widehat{\beta}_1~X_{i1}+\widehat{\beta}_3~X_{i1}-(\widehat{\beta}_0-\widehat{\beta}_1~X_{i1})=\widehat{\beta}_2+\widehat{\beta}_3~X_{i1}\quad (4)$$
Notamos que a curva da diferença entre os sinais analíticos das concentrações quando estamos na situação “Analito em solvente” e “amostra foritificada” é representada pela equação (4). Com isso, para testarmos a igualdade do intercepto, testamos a hipótese nula $\beta_2=0. $ Já no paralelismo é feito pelo teste $\beta_3=0. $ Se os dois coeficientes forem nulos, temos o teste de coincidência.
(há elementos em falta na equação acima)
Modelagem Matricial
Para a construção dos testes de Paralelismo, Igualdade de Intercepto e Coincidência precisamos utilizar o teste F parcial. Para isso, considere o modelo de regressão linear escrito na forma matricial:
$$Y = X\beta + \varepsilon~~~~(5)$$
em que
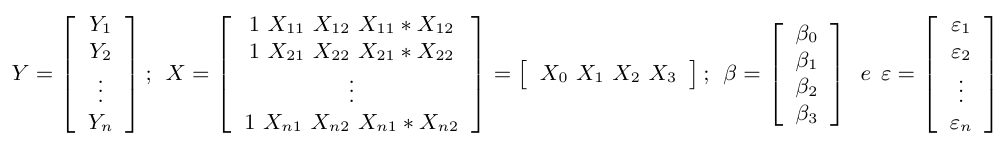
observe que $ X_0, X_1, X_2 $ e $ X_3 $ são vetores referente a cada coluna da matriz $ X $. Desta forma, podemos reescrever o modelo matricial de forma particionada:
$$Y=X_0\beta_0 + X_1\beta_1 + X_2\beta_2 + X_3\beta_3 + \varepsilon .$$
Neste modelo, os estimadores de mínimos quadrado são dados por
$$\hat{\beta} = (X^\prime X)^{-1} X^\prime Y.$$
A soma de quadrados total (SQT) para o modelo matricial (5), é dada por
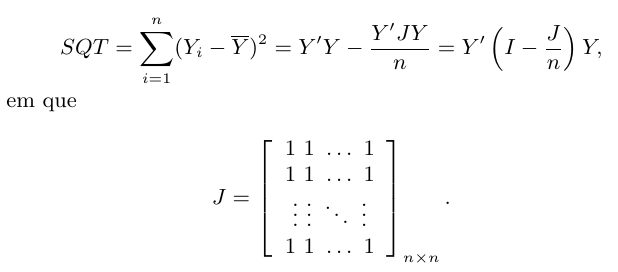
Além disso, de “Propriedades dos Estimadores” temos que a soma de quadrados dos erros (dos resíduos) é dada por
$$SQE=Y^\prime Y-\widehat{\beta}\prime X^\prime Y=Y^\prime (I-X (X^\prime X )^{-1}X^\prime )Y=Y^\prime(I-H)Y.$$
A matriz $ I $ é a matriz identidade com dimensão n x n e a matriz $ H=X [X^\prime X]^{-1}X^\prime $ é chamada matriz chapéu que transforma o vetor de respostas Y no vetor de valores ajustados $ \widehat{Y} $.
Desta forma, obtemos que a soma de quadrados da regressão é dada por
$$SQR=SQT-SQE=\left(Y^\prime Y-\frac{Y^\prime JY}{n}\right)-(Y^\prime Y-\widehat{\beta}^\prime X^\prime Y)=\widehat{\beta}^\prime X^\prime Y-\frac{Y^\prime JY}{n}.$$
e o quadrado médio do erro $ (QME) $ é calculado por
$$QME = \frac{SQE}{n-3-1}$$
.
Utilizando essas definições, podemos definir os testes para comparação das curvas.
Teste de Igualdade do Intercepto
No teste de igualdade de intercepto, as hipóteses de interesse são:
$$~\beta_2\neq 0$$
(há elementos em falta na equação acima)
Denominamos por modelo reduzido o modelo supondo que $ H_0 $ é verdadeiro. Utilizando a notação matricial particionada temos que o modelo reduzido é
$$Y=X_0\beta_0+X_1\beta_1+X_3\beta_3$$
Então, a matriz $ X $ para o modelo reduzido, denominada por $ X_R $ e o vetor de parâmetros $ \beta_R $ são dados por
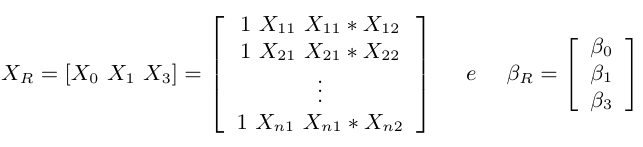
Assim, podemos calcular o $ SQR $ do modelo reduzido por
$$SQR(\beta_R)=\hat{\beta_R}^{\prime}X^{\prime}_R Y-\frac{Y^{\prime}JY}{n}$$
Então, a soma de quadrados de regressão de $ \beta $ dado que $ \beta_R $ ja esta no modelo é calculado por
$$SQR(\beta|\beta_R)=SQR(\beta)-SQR(\beta_R) = \hat{\beta}^{\prime}X^{\prime}Y-\frac{Y^{\prime}JY}{n}-(\hat{\beta}_R^{\prime}X^{\prime}_R Y-\frac{Y^{\prime}JY}{n}) = \hat{\beta}^{\prime}X^{\prime}Y-\hat{\beta}_R^{\prime}X^{\prime}_R Y$$
Com $ (4-(4-1))=1 $ grau de liberdade. Essa soma de quadrados da regressão parcial representa a quantidade adicional que teríamos na soma de quadrados da regressão ao adicionar 1 covariavel no modelo reduzido.
Então, podemos testar a hipótese nula $\beta_2=0 $ utilizando a estatística:
(há elementos em falta na equação acima)
$$F_0 = \frac{SQR(\beta|\beta_R)/1}{QME} \sim F_{1,(n-4)}$$
Portanto, se $ F_0> F_{\alpha, 1,(n-4)} $ rejeitamos a hipótese nula, ou seja, concluímos que $ \beta_2 \not= 0 $, no qual $ \alpha $ é o nível de significância proposto. Na RDC 166 utilizamos $ \alpha=0,05 $.
(imagem em falta)
O P-valor no teste do intercepto é dado por $ \mathbb{P}[F_{1,n-4} > F_0] $. Como sempre, rejeitamos $ H_0 $ se o P-valor for menor que o nível de significância proposto. Na RDC 166 utilizamos $ \alpha=0,05 $.
(imagem em falta)
Teste do Paralelismo
Conforme descrito na RDC 166, o teste de paralelismo avalia o impacto da matriz na metodologia analítica. Caso as retas sejam paralelas, dizemos que o impacto é nulo e neste caso, podemos desenvolver o método em solvente. Para testarmos o paralelismo entre as retas, testamos as seguintes hipóteses:
$$~\beta_3\neq 0$$
(há elementos em falta na equação acima)
Nesse caso, o modelo reduzido supondo que $ H_0 $ é verdadeiro é dado por
$$Y=X_0\beta_0+X_1\beta1+X_2\beta_2$$
Então, a matriz regressão $ X $ para o modelo reduzido será denotada por $ X_R $ e o vetor de parâmetros será denotado $ \beta_R $ tal que
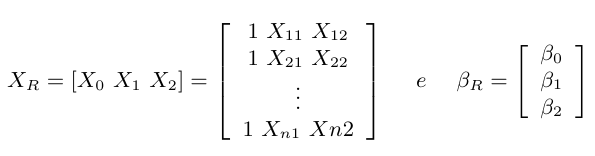
Assim, podemos calcular o $ SQR $ do modelo reduzido por
$$SQR(\beta_R)=\hat{\beta}_R^{\prime}X^{\prime}_R Y-\frac{Y^{\prime}JY}{n}$$
Então, a soma de quadrados de regressão de $ \beta $ dado que $ \beta_R $ ja esta no modelo é calculado por
$$SQR(\beta|\beta_R)=SQR(\beta)-SQR(\beta_R) = \hat{\beta}^{\prime}X^{\prime}Y-\frac{Y^{\prime}JY}{n}-(\hat{\beta}_R^{\prime}X^{\prime}_R Y-\frac{Y^{\prime}JY}{n}) = \hat{\beta}^{\prime}X^{\prime}Y-\hat{\beta}_R^{\prime}X^{\prime}_R Y$$
Com $ (4-(4-1))=1 $ grau de liberdade. Essa soma de quadrados da regressão parcial representa a quantidade adicional que teríamos na soma de quadrados da regressão ao adicionar 1 covariavel no modelo reduzido.
Assim, podemos testar a hipótese nula $ \beta_3=0 $ utilizando a estatística:
(há elementos em falta na equação acima)
$$F_0 = \frac{SQR(\beta|\beta_R)/1}{QME} \sim F_{1,(n-4)}$$
Portanto, se $ F_0> F_{\alpha, 1,(n-4)} $ rejeitamos a hipótese nula, ou seja, concluímos que $ \beta_3 \not= 0 $, no qual $ \alpha $ é o nível de significância proposto. Na RDC 166 utilizamos $ \alpha=0,05 $.
(imagem em falta)
O P-valor no teste de paralelismo é dado por $ \mathbb{P}[F_{1,n-4} > F_0] $. Como sempre, rejeitamos $ H_0 $ se o P-valor for menor que o nível de significância proposto. Na RDC 166 utilizamos $ \alpha=0,05 $.
(imagem em falta)
Teste descrito na RDC 166
A seguir, vamos mostrar que o teste descrito na RDC 166 é equivalente ao teste F-parcial descrito acima. Na RDC 166, tomamos as duas retas de forma independente. Para isto, consideramos os modelos de regressão linear simples,
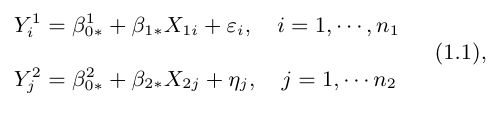
nos quais $ \varepsilon_{i} $ e $ \eta_j $ são variáveis aleatórias independentes com distribuição normal com média zero e variância $ \sigma^2 $. O Teste de Paralelismo é equivalente a
$$~\beta_{1*}\neq \beta_{2*}$$
(há elementos em falta na equação acima)
A RDC 166 propõe a estatística do teste
$$T_0 = \frac{\hat{\beta}_{1*} - \hat{\beta}_{2*}}{s(\hat{\beta}_{1*},\hat{\beta}_{2*})},$$
no quais $ \hat{\beta}_{1*} $ é a estimativa de mínimos quadrados de $ \beta_{1*} $ utilizando as $ n_1 $ observações da curva referente ao “analito em solvente”, $ \hat{\beta}_{2*} $ é a estimativa de mínimos quadrados de $ \beta_{2*} $ utilizando as $ n_2 $ observações da curva referente a “amostra fortificada” com o analito. Como a variância do erro experimental $ \varepsilon_{i} $ e a variância do erro experimental $ \eta_j $ são iguais $ (\sigma^2) $, uma estimativa para o desvio padrão da diferença $ \hat{\beta}_{1*} - \hat{\beta}_{2*} $ é dado por
$$s(\hat{\beta}_{1*},\hat{\beta}_{2*}) =\sqrt{ s^2_p \left[\frac{1}{(n_1-1)s^2_{X_1}} + \frac{1}{(n_2-1)s^2_{X_2}}\right]},$$
nos quais $ s^2_{X_1} $ é a variância amostral de $ X_1 $ e $ s^2_{X_2} $ é a variância amostral de $ X_2 $. Neste caso, a variância agrupada $ s^2_p $ é dada por
$$s^2_p = \frac{(n_1 - 2) QME^{1} + (n_2 -2) QME^{2}}{n_1 + n_2 -4},$$
nos quais $ QME^{1} $ representa o quadrado médio do resíduo para o primeiro grupo e $ QME^2 $ representa o quadrado médio do resíduo para o segundo grupo.
Como apresentado no módulo de comparação de médias, sob $ H_0 $, a estatística $ T_0 $ tem distribuição t-Student com $ n_1 + n_2 -4 $ graus de liberdade. Assim, podemos utilizar um teste t-Student de comparação de médias para avaliar o paralelismo estre as duas retas. Por definição, sabemos que o quadrado de uma distribuição t-Student com $ \nu $ graus de liberdade é igual a uma distribuição F com $ 1 $ grau de liberdade no numerador e $ \nu $ graus de liberdade no denominador. A partir desta equivalência, concluímos que o teste F-parcial e o teste proposto na RDC 166 são equivalentes.
Teste de Coincidência
Para testarmos a coincidência entre as retas (teste de igualdade), testamos as seguintes hipóteses:

(há elementos em falta na equação acima)
Assim, podemos calcular o $ SQR $ do modelo reduzido por
$$SQR(\beta_R)=\hat{\beta}_R^{\prime}X^{\prime}_R Y-\frac{Y^{\prime}JY}{n}$$
Então, a soma de quadrados de regressão de $ \beta $ dado que $ \beta_R $ ja esta no modelo é calculado por
$$SQR(\beta|\beta_R)=SQR(\beta)-SQR(\beta_R) = \hat{\beta}^{\prime}X^{\prime}Y-\frac{Y^{\prime}JY}{n}-(\hat{\beta}_R^{\prime}X^{\prime}_R Y-\frac{Y^{\prime}JY}{n}) = \hat{\beta}^{\prime}X^{\prime}Y-\hat{\beta}_R^{\prime}X^{\prime}_R Y$$
Com $ (4-(4-2))=2 $ graus de liberdade. Essa soma de quadrados da regressão parcial representa a quantidade adicional que teríamos na soma de quadrados da regressão ao adicionar 2 covariaveis no modelo reduzido.
Então, podemos testar a hipótese nula $\beta_2=\beta_3=0 $ utilizamos a estatística:
(há elementos em falta na equação acima)
$$F_0 =\frac{SQR(\beta|\beta_R)/2}{QME} \sim F_{2,(n-4)}$$
Portanto, se $ F_0> F_{\alpha, 2,(n-4)} $ rejeitamos a hipótese nula, ou seja, concluímos que pelos menos um dos $ \beta_i\not= 0 $, i=2,3.
Os métodos das equações (1) e (1.1) são equivalentes, conforme cálculos descritos nesta seção e da referência Guedes et al [6]. Logo, basta aplicarmos o modelo (1) para testarmos a igualdade do intercepto, paralelismo e coincidência.
(imagem em falta)
O P-valor no teste de coincidência é dado por $ \mathbb{P}[F_{2,n-4} > F_0] $. Como sempre, rejeitamos $ H_0 $ se o P-valor for menor que o nível de significância proposto. Na RDC 166 utilizamos $ \alpha=0,05 $.
(imagem em falta)
Exemplo 1.3.1
A seguir, apresentamos os dados coletados.
| Concentração | Efeito Matriz | Área | Concentração | Efeito Matriz | Área | Concentração | Efeito Matriz | Área |
|---|---|---|---|---|---|---|---|---|
| 0,794 | com | 723322846 | 0,893 | sem | 812652587 | 1,091 | com | 994255845 |
| 0,794 | com | 722919388 | 0,893 | sem | 812405048 | 1,091 | com | 995371432 |
| 0,794 | com | 723367802 | 0,893 | sem | 812521869 | 1,091 | com | 994974613 |
| 0,794 | com | 724423578 | 0,893 | sem | 810445552 | 1,091 | sem | 988750606 |
| 0,794 | com | 725106579 | 0,893 | sem | 810903886 | 1,091 | sem | 988060333 |
| 0,794 | com | 725529198 | 0,893 | sem | 810248148 | 1,091 | sem | 987646169 |
| 0,794 | com | 724492966 | 0,992 | com | 904384882 | 1,091 | sem | 986719093 |
| 0,794 | com | 724995777 | 0,992 | com | 905029511 | 1,091 | sem | 986946993 |
| 0,794 | com | 726126408 | 0,992 | com | 904400039 | 1,091 | sem | 986765362 |
| 0,794 | sem | 724264113 | 0,992 | com | 904385633 | 1,091 | sem | 991334587 |
| 0,794 | sem | 723751677 | 0,992 | com | 904385383 | 1,091 | sem | 992428032 |
| 0,794 | sem | 724153514 | 0,992 | com | 904452718 | 1,091 | sem | 991727882 |
| 0,794 | sem | 729347610 | 0,992 | com | 904606337 | 1,191 | com | 1071863624 |
| 0,794 | sem | 727573286 | 0,992 | com | 904474647 | 1,191 | com | 1072193435 |
| 0,794 | sem | 727410902 | 0,992 | com | 904903159 | 1,191 | com | 1072139365 |
| 0,794 | sem | 729886571 | 0,992 | sem | 905105673 | 1,191 | com | 1075962819 |
| 0,794 | sem | 729329230 | 0,992 | sem | 905674191 | 1,191 | com | 1077239618 |
| 0,794 | sem | 729014932 | 0,992 | sem | 925365367 | 1,191 | com | 1076029296 |
| 0,893 | com | 811138292 | 0,992 | sem | 925365367 | 1,191 | com | 1076435622 |
| 0,893 | com | 811717343 | 0,992 | sem | 911960028 | 1,191 | com | 1076578829 |
| 0,893 | com | 811610358 | 0,992 | sem | 905178438 | 1,191 | com | 1078667741 |
| 0,893 | com | 813683993 | 0,992 | sem | 903128849 | 1,191 | sem | 1077889788 |
| 0,893 | com | 814581003 | 0,992 | sem | 904650286 | 1,191 | sem | 1075566151 |
| 0,893 | com | 814323181 | 0,992 | sem | 904717291 | 1,191 | sem | 1075419943 |
| 0,893 | com | 812070622 | 1,091 | com | 992132794 | 1,191 | sem | 1070722561 |
| 0,893 | com | 813221641 | 1,091 | com | 992179006 | 1,191 | sem | 1070222746 |
| 0,893 | com | 812033531 | 1,091 | com | 991671498 | 1,191 | sem | 1071099130 |
| 0,893 | sem | 814958107 | 1,091 | com | 989291660 | 1,191 | sem | 1111016773 |
| 0,893 | sem | 815478417 | 1,091 | com | 988669038 | 1,191 | sem | 1059808866 |
| 0,893 | sem | 815697960 | 1,091 | com | 988813205 | 1,191 | sem | 1059211239 |
Testamos o efeito matriz através do software Action Stat e obtemos os seguintes resultados:
- A ferramenta no menu do Action Stat Pharma -> Validação de Métodos -> Comparação de Curvas
(imagem em falta)
- O próximo passo é selecionar os dados de entrada e clicar no botão “Ler”
(imagem em falta)
- Selecionamos as colunas do conjunto de dados referente à Variável Resposta, Variável Explicativa e Método (Efeito Matriz).
(imagem em falta)
- Em “Opções” selecionamos os testes que desejamos e a visualização das curvas através do diagrama de dispersão.
(imagem em falta)
- Selecionamos “Nova Planilha” para mostrar os resultados e clicamos em “Ok”.
(imagem em falta)
A seguir, mostramos alguns dos resultados do Action Stat:
(imagem em falta)
(imagem em falta)
(imagem em falta)
Portanto, observamos que em todos dos testes de comparação de curvas possuem P-Valor maior que 0,05. Então, não detectamos diferença significativa entre as curvas referentes ao “analito em solvente” e a “amostra fortificada” ao nível de significância de 5%. Portanto, as retas são coincidentes.
(imagem em falta)